本博客将探讨其中之一 LangChain的代理商:the 带有反应逻辑的聊天代理. 有很多 LangChain 中提到的代理人 LangChain文档, however, we are just going to focus on the 反应 代理.
那么什么是 反应 代理按 LangChain文档?
此代理使用 反应 框架,仅根据工具的描述来确定使用哪个工具. 可以提供任意数量的工具. This 代理 requires that a description is provided for each tool.
Note: This is the most general purpose action 代理.
本博客还介绍了一个聊天代理的简单实现,它使用了打包在其中的3个工具 LangChain v.0.0.220. For more details about our playground 代理 about please see below.
主要思想
的 带有反应逻辑的聊天代理 has access to a specific list of tools and to a Large Language Model (LLM). 在收到用户生成的消息后,聊天代理会询问LLM哪个工具最适合回答这个问题. Optionally it might also send the final answer.
它可能会选择一个工具. 如果是这种情况,则针对工具执行问题或关键字. 然后,该工具返回一个输出,然后用于LLM再次计划下一步要做什么:要么选择另一个工具,要么给出最终答案.
因此,代理使用LLM来计划在循环中下一步做什么,直到找到最终答案或放弃.
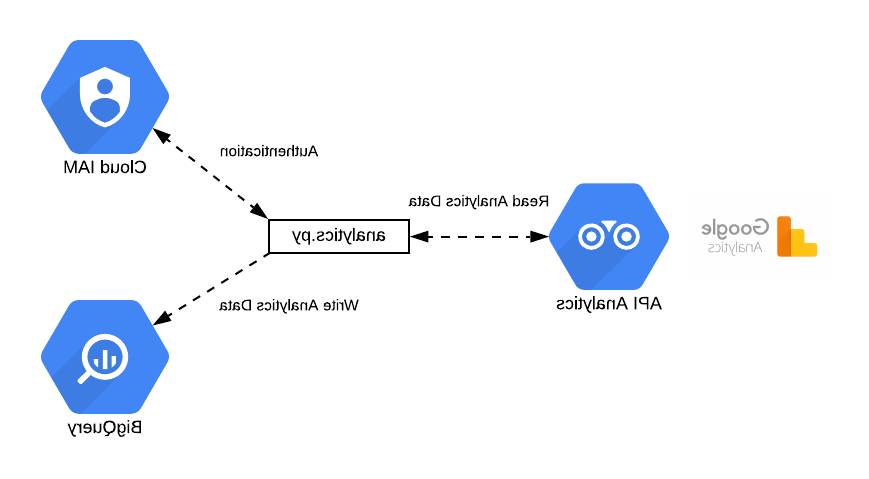
聊天代理流程
Here is the chat 代理 flow according to the LangChain 实现:

在web或命令行应用程序的典型场景中,流程可以分为两个部分:
- 设置流:用于设置代理的主要部分,包括工具和LLM.
- 执行流程:由两个循环组成. 外部循环处理用户输入,内部循环处理代理与工具和LLM的交互.
理解执行流
设置流程通常只是主执行流程的顺序前奏:

的 flow executes the following steps:
- 接受 用户输入. 用户输入通常是通过web、移动设备或命令行UI输入的问题.
- 代理开始工作: it asks the LLM which tool to use to give the final answer.
- 在这个阶段, 第一进程网关 达到. 它有三个输出:
- 使用工具: the LLM decided to use a specific tool. 的 flow continues below in “工具回复”
- 给出基于法学硕士的答案: 的 LLM came up with the final answer
- 回答不明白法学硕士的答案是不确定的. 进程在这里退出,并出现错误. - 工具回复: 的 tool sends a message to the second gateway
- 的 第二工作流网关 达到. 它有三种可能的结果:
- normally the output of the tool is routed to the LLM. We return to the initial step of the 代理 loop.
- if the executed tool is marked as a “返回工具” the response from the tool is the final answer
-错误条件发生:如果工具抛出错误或超时发生或达到最大尝试量,则进程退出并出现错误.
A Very Simple 维基百科, DuckDuckGo, Arxiv 代理
We have built a very simple 代理 that uses three built-in LangChain 代理人:
- 维基百科 (备受喜爱的在线百科全书)
- Arxiv (an online archive for scientific papers)
- DuckDuckGo (一个注重隐私的搜索引擎)
我们使用了这三个代理,因为它们在LangChain中是开箱即用的,也不需要任何注册或付费订阅.
这个命令行应用程序可以用来谈论不同的主题,并提出以下问题:
- 唐老鸭是谁??
- 今天伦敦的天气怎么样?
- 爱因斯坦是谁??
- 谁将是下一届美国总统选举的总统候选人?
- 2020年全球最大的博彩平台神经网络注意力层最相关的出版物是哪些?
Below is an excerpt of an interaction with the tool:
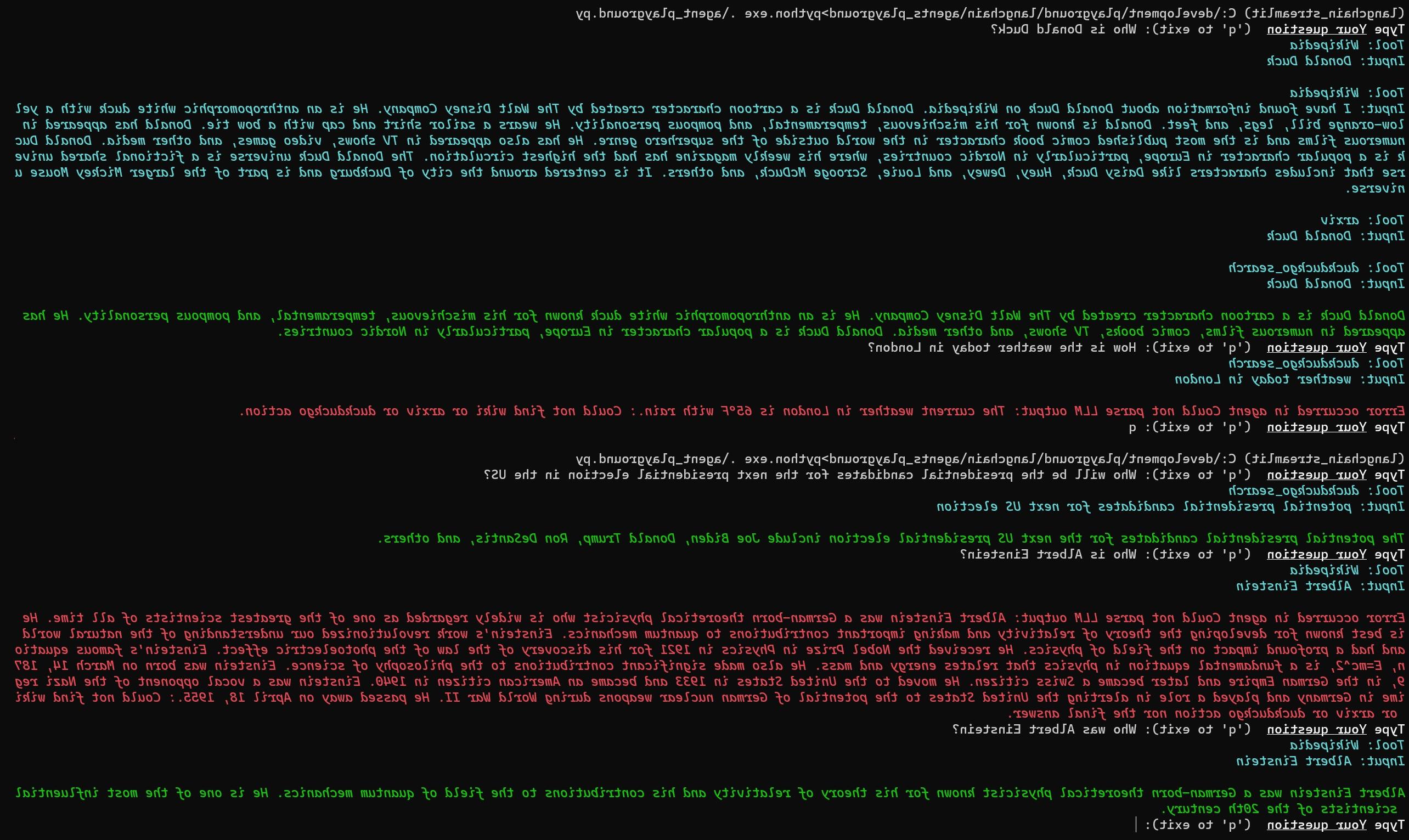
We have tried to colour-code the outputs of the tool:
- 绿色:响应成功
- red: error message with some explanation
- blue intermediate step; typically mentioning the tool and the question sent to the tool
实现
Our little chat application can be found in this GitHub repository:
GitHub - gilfernandes/代理_playground:一个基于LangChain代理的小演示项目.
Small demo project with a functional LangChain based 代理. - GitHub - gilfernandes/代理_playground: Small demo…
主代理代码已输入 代理_playground.py
的 代理 is configured using this code:
类配置():
"""
Contains the configuration of the LLM.
"""
模型= 'gpt-3.5-turbo-16k”
# model = 'gpt-4'
llm = ChatOpenAI(model=model, temperature=0)
cfg = Config()我们使用gpt-3.你可以看到5个API.
的 代理 is setup in this function below:
def create_代理_executor(cfg: Config, action_detector_func:可调用的, verbose: bool = False) -> 代理Executor:
"""
Sets up the 代理 with three tools: wikipedia, arxiv, duckduckgo search
:param cfg 的 configuration with the LLM.
:param action_detector_funcc一个更灵活的输出解析器实现, better at guessing the tool from the response.
:param verbose whether there will more output on the console or not.
"""
tools = load_tools(["wikipedia", "arxiv", "ddg-search"], llm=cfg.llm)
代理_executor: 代理Executor = initialize_代理(
工具,
cfg.llm,
代理= 代理Type.CHAT_ZERO_SHOT_REACT_DESCRIPTION,
verbose =详细
)
代理 = 代理_executor.代理
代理.output_parser = ExtendedChatOutputParser(action_detector_func)
返回代理_executorAs you can see the three tools “维基百科”, “arxiv”, 和“ddg-search”在这里加载,代理执行器在这里使用 CHAT_ZERO_SHOT_REACT_DESCRIPTION类型.
You may also notice that we have added a custom output parser. 的 output parser is tasked with parsing the output coming from the LLM. 我们希望有一个更灵活的输出解析器实现,以便更好地检测要使用的工具——这主要是因为我们在测试期间得到了大量的错误. This is the implementation of the tool which can be found in the file: chat_output_parser.py.
This is the custom implementation of the output parser:
class ExtendedChatOutputParser(ChatOutputParser):
action_detector_func:可调用的
def __init__(self, action_detector_func:可调用的):
super ().__init__(action_detector_func=action_detector_func)
def parse(self, text: str) -> Union[代理Action, 代理Finish]:
includes_answer = FINAL_ANSWER_ACTION in text
试一试:
动作=自我.action_detector_func(文本)
响应= json.负载(行动.带())
includes_action = "action" in response
if includes_answer and includes_action:
提高OutputParserException (
"Parsing LLM output produced a final answer "
"和一个可解析的动作:{text}"
)
print(get_colored_text(f"Tool: {response['action']}", "blue"))
print(get_colored_text(f"Input: {response['action_input']}", "blue"))
print ()
返回代理Action (
响应“行动”,响应.获取("action_input",{}),文本
)
例外情况如下:
如果没有包括答案:
引发OutputParserException(f"无法解析LLM输出:{text}: {str(e)}")
返回代理Finish (
{“输出”:文本.分割(FINAL_ANSWER_ACTION) [1].带()},文本
)此实现允许指定用于检测动作的自定义函数,或者换句话说,指定下一步使用哪个工具.
我们编写的用于从LLM输入检测下一个的函数可以在 代理_playground.py:
def action_detector_func(文本):
"""
Method which tries to better understand the output of the LLM.
:param text: the text coming from the LLM response.
:返回一个json字符串,其中包含接下来要查询的工具的名称和该工具的输入.
"""
分割=文本.分割(“的”)
if len(splits) > 1:
# Original implementation + json snippet removal
返回重新.Sub (r"^json", "",拆分[1])
其他:
Lower_text =文本.低()
tool_tokens = ["wiki", "arxiv", "duckduckgo"]
Token_tool_mapping = {
“维基”:“维基百科”,
:“arxiv arxiv”,
:“duckduckgo duckduckgo_search”
}
对于tool_tokens中的token:
如果token在lower_text中:
返回json.转储({
“行动”:token_tool_mapping(令牌),
“action_input”:文本
})
抛出OutputParserException('无法找到wiki或arxiv或duckduckgo操作或最终答案').')在这个函数中, 我们不仅要查找预期的JSON输出,还要查找可能指示使用下一个工具的单词.
使用法学硕士的一个问题是,它们在某种程度上是不可预测的,并且以意想不到的方式表达自己, 因此,这个函数只是试图以一种更灵活的方式捕捉法学硕士想要传达的信息.
观察
我们注意到,LangChain使用了一个特殊的提示符来查询LLM如何对输入做出反应. 的 prompt used in this library is this one:
Answer the following questions as best you can. You have access to the following tools:
维基百科: A wrapper around 维基百科. Useful for when you need to answer general questions about people, 的地方, 公司, 事实, 历史事件, 或者其他科目. 输入应该是一个搜索查询.
arxiv: arxiv的包装.org Useful for when you need to answer questions about Physics, 数学, 计算机科学, 定量生物学, 定量金融学, 统计数据, 电气工程, and Economics from scientific articles on arxiv.org. 输入应该是一个搜索查询.
duckduckgo_search: A wrapper around DuckDuckGo Search. Useful for when you need to answer questions about current events. 输入应该是一个搜索查询.
的 way you use the tools is by specifying a json blob.
具体地说, 这个json应该有一个' action '键(包含要使用的工具的名称)和一个' action_input '键(包含工具的输入到这里).
“action”字段中应该包含的值只有:维基百科、arxiv、duckduckgo_search
JSON_BLOB美元应该只包含一个动作,不返回多个动作的列表. Here is an example of a valid JSON_BLOB美元:
```
{
“行动”:$ TOOL_NAME
“action_input”:$输入\ n}
```
始终使用以下格式:
Question: the input question you must answer
Thought: you should always think about what to do
行动:
```
JSON_BLOB美元
```
Observation: the result of the action
... (this Thought/Action/Observation can repeat N times)
心想:我现在知道最后的答案了
Final Answer: the final answer to the original input question
开始! Reminder to always use the exact characters `Final Answer` when responding.'提示信息通过系统消息发送给LLM,同时发送的还有来自工具响应的问题或观察结果.
我们想知道你如何指导法学硕士在这种情况下的行为.
最终的想法
在这个故事中, 我们试图描述一个简单的聊天代理是如何工作的,并试图理解聊天代理的内部机制. 您可以使用额外的工具来增强大型语言模型的功能,这些工具可以将法学硕士的知识扩展到他们通常无法访问的领域. 法学硕士不是在旧的知识基础上进行培训,而是使用公开可用的信息. 如果你想与法学硕士一起获取前沿新闻,代理是一个不错的选择.
的re is a lot more you can do with 代理s, like letting them engage in adversarial scenarios or against code bases, but we will be looking at those scenarios in our upcoming stories.